I am having issues when I am tracking a website. I have been running it for a while but I have an issue that sometimes comes up and can become a major issue later on. I notice that a “snapshot” or “sieve” is generated even if the website fails to load completely. What it does, it just takes a snapshot and logs it as a change for that site of tracking item.
This may be ok, but I want it to not generate a sieve if, let’s say, more than 500 words/items change on a particular page. I’ve already set it up and that does at least not provide me with a notification but the problem is that it DID take a snapshot of the page and when it runs again, it compares it to that sub-par page, which could be an issue as there could have been particular items that did change that were needed to be notified about.
There are two things that I think are needed, or could be added:
A way to eliminate or categorize different sieves to use for comparison later on:
Ideally, I can just keep the ones I would like to keep and maybe “nickname” or categorize some of the long list of sieves that have been run in order to compare in the future. As in I can compare a: “May 2023” vs. “Sep 2023” by easily categorizing them.
It would be good to have a feature in which it only generates a snapshot IF certain conditions are met. Right now, conditions seem to only be set for notifications, but not setup to run/not-run a snapshot generation. I have the following issue and when this issue happens I would like it to just skip and/or run twice if more than X text characters change.
Thanks for sharing your use case, @armian10. This makes sense. An incorrectly loaded page can add noise to the change history and trigger unwanted notifications.
We have planned to build a feature which is close to the 2nd suggestion. The plan is to accept a list of validation rules that will be executed as soon as the page has loaded but before its content has been saved. If the validation rules raise an error, that check will be marked as an error in the log instead of appearing in the change history.
This makes sense. Any timeline to when this would be implemented?
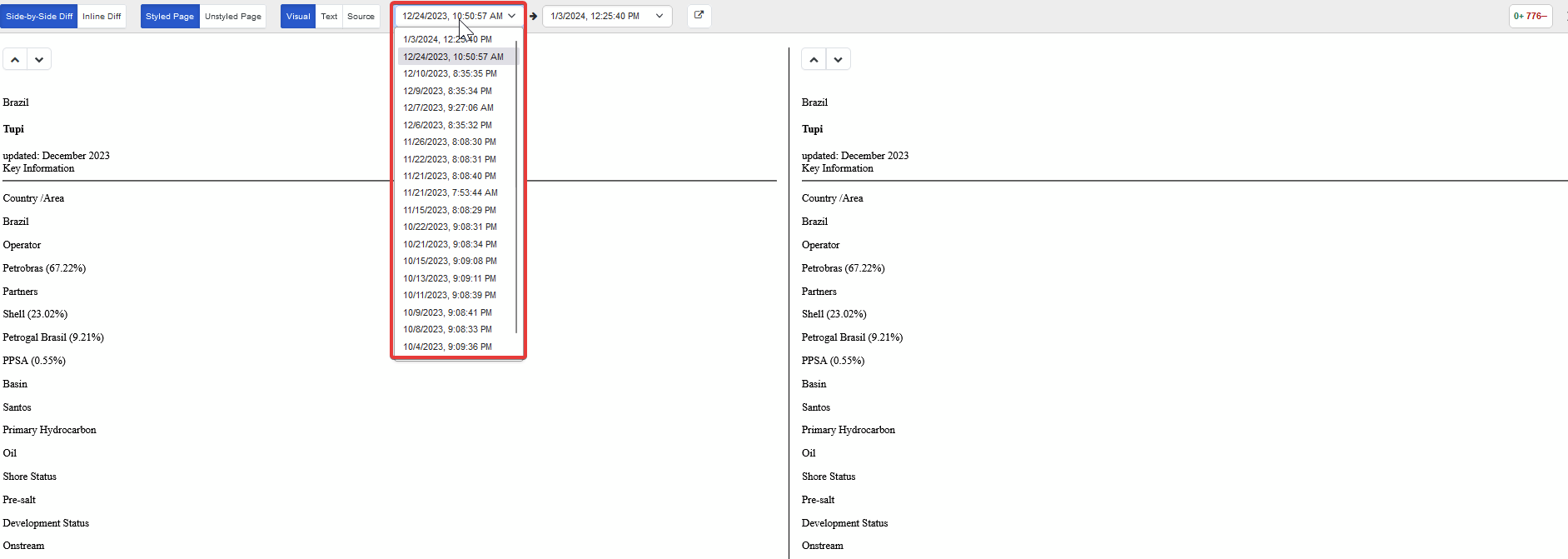
Also, my suggestion on number 1 for a “tagging” or some kind of “baseline” of comparison of some kind would be really useful. Since we are updating reports to clients on a monthly/quarterly basis, I would like to quickly find/compare versions to previous versions. Any ideas or feature enhancements on this topic would be helpful.
Not to mention, the ability to archive/delete sieves that may not be worth keeping in the dropdown would be another improvement.
Thanks again and look forward to hearing when these things can be implemented!
Note that we call a monitor a sieve, and its associated items in change history sieve_data.
We have considered letting users delete a sieve_data as a nice of have feature. It hasn’t been formally planned yet because of a few technical challenges because of the way sieve_data are synced across devices.
Labelling and archiving needs some more thought as they could be related.
How do you envision archiving to work? Older sieve_data are truncated automatically. Should archived sieve_data be preserved and not deleted? With time, they will gradually be collected at the bottom of the list as other sieve_data around it are deleted.
Thanks for that timeframe, I look forward to seeing it deployed.
As for your question, I can imagine archiving information as to not keep it top of mind for the dropdown list of sieve_data’s for historical purposes. I realize there may be a need sometimes to archive, but not delete information, this happens all the time.
From a user standpoint, I’d like to quickly compare labeled sieve_data’s for each monitor because currently I have to remember the date of each sieve data that I’d like to compare, and there may be multiple sieve_data’s with at least the same day… From my use and the use case of my company, this would be quite beneficial for the QC processes and comparison/lookbacks that we do regularly.